Using Auto-encoder for Fraud detection implemented in Knime
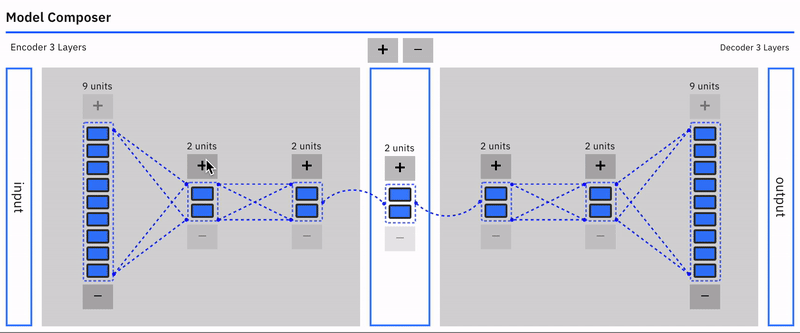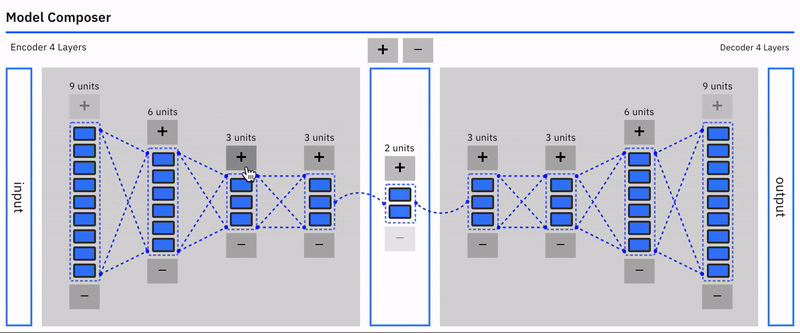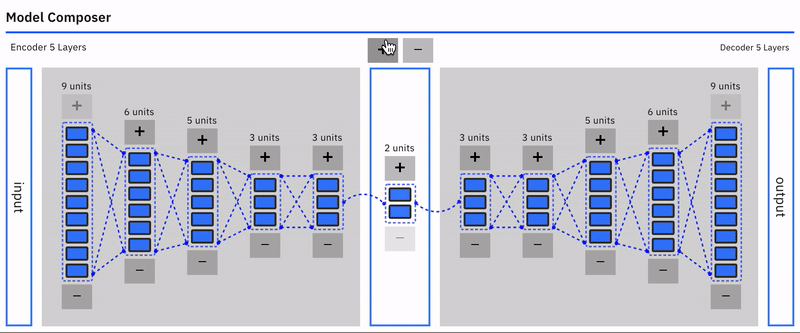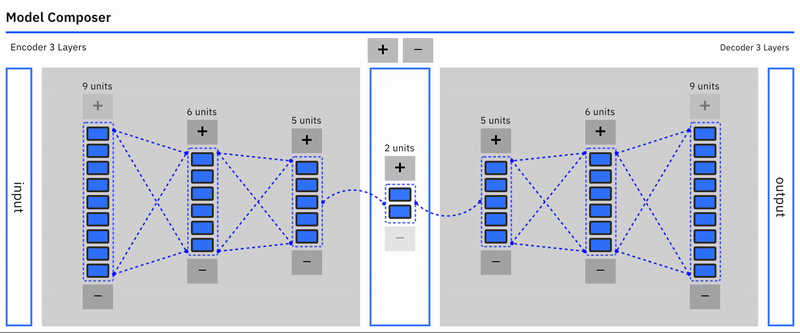
Auto-encoders are an unsupervised learning technique using neural networks to learn representations.
Specifically, we will design a neural network architecture with a bottleneck that forces a compressed knowledge representation of the original input. This compression and subsequent reconstruction would be complicated if the input features were completely independent of one another. However, if some structure exists in the data (ie. correlations between input features), this structure can be learned and consequently leveraged when forcing the input through the network’s bottleneck.
Autoencoders
The dataset for this will be downloaded from here.
Here we have data in the .csv format, so we will use the CSV reader node. Let us configure this node and execute this node.

CSV reader node

Configuring CSV reader node
After examining the dataset, we will divide it into transactions that are legal and those that are not. The value 0 in the class column indicates a legal transaction, and value 1 indicates an illegal transaction or fraud. For this, we will use the Row splitter node. Let’s set this up.

Row splitter node

Configuring row splitter node
Now, let's split the data for training and validation. For this here we will use the Partitioning node. Let's configure this and execute it and see the output.

Partitioning node

Configuring partitioning node

The output of the partitioning node
Now again split the data for validation. Configure this and execute it.

Partitioning 10% for validation

Configuring partitioning node
Now, we’ll use the Normalizer node to normalize the data, and we’ll use min-max normalization. Let’s configure this node, execute it, and see what the output is.
One of the most common methods for normalizing data is min-max normalization. For each feature, the minimum value is converted to a 0, the maximum value is converted to a 1, and all other values are converted to decimals between 0 and 1.

Normalizer node

Configuration of Normalizer node
Now concate the output of portioned table and the row splitter table by using Concatenate node.
Configure this node and execute this node.

concatenate node

configuring this node
Now save the normalized model node using the model writer node configure this node and execute it.

model writer node

configuring this node where we have to save our model
Now also apply the normalized model for the validation or testing data using the normalization apply node. Configure it and execute this node.

Normalizer(Apply) node

Configuring the Normalizer(Apply) node

The data preprocessing part is completed
Now let's create the model of the autoencoder using the Keras Input layer network node. Configure this node and execute this node.

Keras Input Layer node

configuration of Keras Input layer node
Now for creating the dense layer or hidden layer we will use the Keras dense layer node. Configure this node and execute it.

Keras Dense layer node

configuration of Keras Dense layer node
Similarly, perform the same operations for all the nodes as shown below.

Created autoencoder model
Let us now apply supervised learning to a Keras deep learning network. Configure and execute this node using the Keras network learner node.
If you find a dependency error in this node please refer to my previous blog.

Keras Network learner node
Here in this node, we will use the loss function equal to MSE and set the Adam optimizer.
The mean squared error is calculated using the average of the squared differences between the predicted and actual values. Regardless of the sign of the predicted and actual values, the result is always positive, and an excellent value is 0.0. The squaring implies that bigger mistakes result in more errors than smaller errors, indicating that the model is penalized for making larger errors.

Configuring the input data in the Keras network learner node

Configuring output layer

Setting epoch, batch, Adam optimizer
Now let us perform the execution using the Keras executor node. Configure this node and execute the node.

Keras Executor node

Configuring Keras network executor node

Workflow till the above steps
Let's optimize the threshold using the threshold optimization node.

Threshold optimization
Configure the math formula node and execute this node.

Math formula node

configuring the math formula node
The first row of a data table where new flow variables are defined. The variable names are defined by the column names, and the variable assignments (i.e. the values) are defined by the values in the row. We’ll use the Variable to Table Row node for this.

Variable to table row node

Configuring variable to table row node
For extracting the output column here we will use the rule-based engine node, configure this node and execute this node.

Rule Engine Node

Configuring the Rule Engine Node
Now convert the number to string using the number to string node.

Converting a number to a string node

configuring the number to a string node
Now let’s observe the accuracy of our model using the scorer node.

Scorer Node

Configuring the node

output of the scorer node


Final workflow
Let us now put the model into action. We will use the data created by the writer node in this case. If you can’t find the data, you can download it from here.
Because we have data in the formats .csv, .h5, and table, we will use CSV reader, Model Reader, Keras Network Reader node, and table reader node.
Let’s start with the CSV reader node. configure this node and execute this node.

CSV reader node

Configuring CSV reader node
Now read the normalized model that we have created in the training part using the model reader node.

Model Reader Node

Configuring model reader node
Similarly, use the Keras network reader to read the Keras model in.h5 format.

Keras Network reader node

Configuring the Keras Network Reader Node
Let us read the data which is in the table format using the table reader node.

Table reader node

Configuring table reader node

Table to Row node

Configuring the above node

Process workflow for reading the data parameter
Now applying the Normalizer(Apply)

Normalizer (Apply) node

configuration of Normalizer(Apply)
Now, let's execute the Keras Network Executor node.

Keras Network Executor

Configuration of Keras network executor node
Similarly, execute the math formula node from the same configuration as before.


configuration of Math formula node
Now extract the output using a Rule-based engine node.

Rule engine node

Configuration of the rule engine node

Workflow till now
Now convert the table row to a variable using the table row to the variable node.

Table row to variable node

Configuration of a table row to variable node
Now here we will use the case switch start node. Configure this node and execute this node.

Case switch start node

Configuration of case switch start node
If a fraudulent transaction occurs, an email is sent directly to the owner via a send email node.

Send Email node


Configuration of send email node

Final workflow for deployment
As you can see, the image above is a final workflow for deployment, and the image above that is a configuration of the send email node.
Thank You!!!
You can DM me on LinkedIn or Instagram if you have any further questions about Knime/Python Development, Machine Learning / Deep Learning ,Coding, Blogging, or Tech Documentation*. **Special credits to my team members: [Siddhid](https://www.linkedin.com/in/siddhid-gopujkar-209716188/) and [Anshika*](https://www.linkedin.com/in/anshika-yadav-0a69381b7/)
Get your Personality NFT
& Find your Community Everywhere you Go